
I’m pleased to say I’ve received a lovely review from Joe Whittaker in Apr-May Folk London Magazine. This the second review I’ve had for my […]

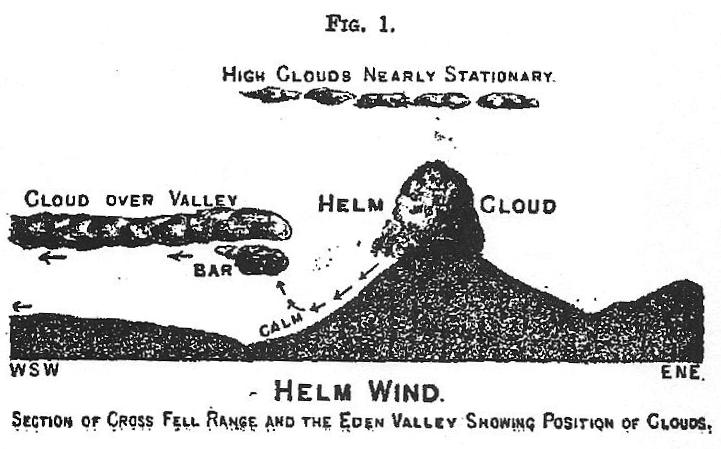
The Helm Winds
Welcome to the Helm Winds landing page. Here, you will find the digital booklet for anyone who purchased the CD or downloaded it digitally, as […]
Official KLOF Magazine Review of Selkie Child EP
I’m thrilled to say that the influential KLOF Magazine have reviewed my debut EP. The review was done by Nigel Spencer, formerly of Folk Police […]

Silkie Child (EP)
Welcome to the landing page for Silkie Child, the EP. Selki Child Booklet: Michelle Laverick – Selkie Child Digital Booklet Selkie Child Release Selkie Child […]

Belle & Sabastian, Leanora Carrington, Horncliffe
Well, what a week I’ve just had – I was up in Glasgow last weekend for Belle & Sebastian’s 2 nights at Kellingove Bandstand – […]

GIG: Horncliffe Music and Beer Festival
I’m thrilled to say I’ve been asked to play at the Horncliffe Music and Beer Festival in July. I was in the area back in […]

GIG-A-HOLIDAY 2026
Well, it’s done. My first ever “gig-a-holiday” is over. So what is a gig-a-holiday? Instead of two weeks on a beach topping up my entirely […]

Gigs in April
So I’ve got some dates coming up at the end of April. There’s a couple of paid gigs together with me rocking up at local […]
Early Responses to the new Helm Winds EP
Batches of the Helm Winds EP in a CD format have gone out to various outlets across the country – and I’ve started to collect […]

New Year: New Single: New Video – The Helm Winds
Happy New Year to everyone. I’m pleased to release the title track from my soon-to-be-released EP. The video was very kindly created by Marry Waterson. […]

BBC Introducing – Christmas Parting Song
I’m very pleased to say once again the BBC have picked up a song of mine. It was released on 1st Dec, and see it […]
Coming soon “The Helm Winds” Collection of Songs
So I have a new collection of songs recorded for your listening pleasure coming soon. I’ve decided not to call it an EP, LP, or […]